


Ejemplo de Process Mining con datos de ubicación

Introducción
Process mining es una técnica potente que se utiliza para analizar, supervisar y mejorar los procesos empresariales extrayendo información de los registros de eventos generados por los sistemas de información. Al examinar los datos registrados durante las operaciones diarias —como marcas de tiempo, nombres de actividades, IDs de caso y usuarios—, el process mining puede visualizar cómo funcionan realmente los procesos en la práctica, descubriendo ineficiencias, desviaciones y cuellos de botella que de otro modo podrían pasar desapercibidos.
El process mining se aplica ampliamente en sectores como la logística, la sanidad, las finanzas y la fabricación. En logística, puede optimizar las operaciones de almacén, hacer seguimiento de los flujos de envío y mejorar la fiabilidad de las entregas. En sanidad, ayuda a hospitales y clínicas a analizar los recorridos de los pacientes, reducir los tiempos de espera y agilizar los procesos de tratamiento. Las instituciones financieras lo utilizan para garantizar el cumplimiento normativo, detectar anomalías en los procesos y mejorar los flujos de incorporación de clientes. En fabricación, ofrece información valiosa sobre el rendimiento de la línea de producción, identifica retrasos en el control de calidad y destaca oportunidades para equilibrar cargas de trabajo o reducir los tiempos de ciclo.
Al hacer transparentes los procesos operativos, el process mining permite a las organizaciones ir más allá de las suposiciones y basarse en datos reales para impulsar mejoras de procesos, controles de cumplimiento y toma de decisiones estratégicas.
En esta entrada del blog, repasamos un ejemplo concreto de process mining basado en datos de ubicación en interiores de un flujo real de fabricación. Usando registros de eventos generados a partir de datos RTLS, demostramos cómo visualizar, validar y optimizar procesos con herramientas como Celonis, IBM Process Mining y PM4Py en Python. Puedes descargar aquí el conjunto de datos de ejemplo y los scripts para seguir el proceso o probarlo con tus propias herramientas:
Beneficios y ventajas del Process Mining
Antes de profundizar en el ejemplo, presentemos primero las tres categorías principales del process mining:
1. Descubrimiento de procesos
Qué hace: Crea automáticamente un modelo de proceso basado en datos reales de registros de eventos.Beneficios:
- Revela cómo funcionan realmente los procesos, incluidas rutas y variaciones ocultas.
- No necesita modelos preexistentes: los construye a partir de los datos.
- Ayuda a las organizaciones a visualizar la realidad operativa frente a las expectativas.
2. Verificación de conformidad
Qué hace: Compara el proceso real (a partir de los registros) con un modelo de referencia existente.
- Detecta desviaciones, ineficiencias y problemas de cumplimiento.
- Facilita las auditorías y las comprobaciones regulatorias.
- Destaca las áreas en las que los procesos se desvían de los procedimientos estándar.
3. Mejora de procesos
Qué hace: Mejora los modelos de proceso existentes utilizando información real basada en datos.
- Identifica cuellos de botella, retrasos y oportunidades de optimización.
- Ajusta los procesos en función del rendimiento operativo.
- Apoya la mejora continua de procesos y la toma de decisiones.
En las siguientes secciones, mostraremos cómo los usuarios pueden aplicar herramientas de process mining existentes para aprovechar datos de ubicación en interiores y registros de eventos para investigar estas tres categorías dentro de sus propios procesos.
Añadir datos de ubicación al process mining tradicional
Cómo se capturan normalmente los registros de eventos
En la mayoría de los casos de uso de process mining, los registros de eventos provienen de sistemas empresariales como ERP, MES o WMS. Estos sistemas generan registros cuando un usuario realiza una acción digital, como escanear un código de barras, confirmar un pedido o completar una tarea. Cada registro contiene tres elementos clave: un ID de caso, un nombre de actividad y una marca de tiempo.
Esto funciona bien para flujos de trabajo digitales, pero se queda corto cuando pasos clave del proceso ocurren en el mundo físico, como mover mercancías por una fábrica o trasladar pacientes en un hospital.
Cómo los datos de ubicación mejoran el Process Mining
Al usar datos de ubicación en tiempo real con geofencing, es posible registrar eventos automáticamente en función del movimiento físico. Por ejemplo:
- Un palé que entra en una zona de producción activa “Inicio de producción”
- Una carretilla elevadora que llega al área de expedición activa “Listo para envío”
Este método genera registros de eventos totalmente estructurados sin intervención manual, lo que lo hace ideal para fabricación, logística o sanidad, donde muchos pasos del proceso no se registran digitalmente.
Ventajas de este enfoque:
- Captura acciones del mundo real que los registros de software no recogen
- Automatiza el registro sin interacción de los trabajadores
- Refleja el flujo real del proceso, no solo el planificado
Añadir datos basados en ubicación tiende un puente entre las operaciones físicas y el process mining, permitiendo un análisis de procesos más completo y preciso.
Descubre la plataforma Pozyx
La plataforma Pozyx reúne datos de posicionamiento en interiores y exteriores para ofrecer visibilidad total de los activos, automatización y análisis basados en la ubicación para logística y fabricación.
Plataforma PozyxCómo la plataforma Pozyx proporciona los datos para el Process Mining
El ejemplo que vamos a comentar procede de una planta de fabricación con dos líneas de producción. Cada trabajo debe pasar por distintas ubicaciones de la instalación antes de estar listo para su envío al cliente.
El cliente quiere obtener información automática sobre su proceso de producción. Para lograrlo, se hará un seguimiento de cada trabajo en la planta.
Seguimiento de trabajos en tiempo real mediante tecnología UWB
Para lograr este seguimiento, los trabajos que fluyen por el proceso se rastrean mediante etiquetas UWB. Estos rastreadores permiten un seguimiento preciso de los trabajos y nos ayudan a determinar cuánto tiempo pasa cada trabajo en una ubicación concreta, definida por una geocerca en el mapa.
Esta tarea puede ser gestionada por el Pozyx UWB Real Time Location System (RTLS). Este producto proporciona el hardware necesario (etiquetas y anclas) y el servidor de posicionamiento que ofrece actualizaciones de posición en tiempo real de cada trabajo.
De los datos de posición a los registros de eventos: el papel de la plataforma Pozyx
Las posiciones procedentes del RTLS pueden gestionarse fácilmente con la plataforma Pozyx. La plataforma Pozyx permite a los usuarios añadir lógica de negocio a los datos de ubicación. Más concretamente, un usuario puede configurar dentro de la plataforma un proceso que defina cuándo empieza y termina un trabajo. Una vez configurado esto, la plataforma Pozyx generará un flujo de eventos que hará seguimiento de cada trabajo y de su historial de ubicaciones.


Es importante señalar que, aunque la plataforma Pozyx se integra perfectamente con el Pozyx UWB RTLS, no se limita a él. Cualquier sistema RTLS preciso capaz de proporcionar actualizaciones de posición fiables puede conectarse a la plataforma Pozyx para aprovechar las capacidades que se describen a continuación.
Una vez completada la configuración, la forma más sencilla de avanzar es utilizar nuestra herramienta de informes para generar automáticamente un informe de process mining. Este informe, entregado como archivo Excel o CSV, puede importarse después en herramientas específicas de process mining para un análisis más profundo.
Analizando el ejemplo de process mining
A continuación, ilustraremos algunas técnicas básicas de process mining utilizando herramientas muy conocidas para process mining.
Primera vista de nuestro proceso con Celonis Business Miner
Primero cargaremos nuestro informe en la aplicación de process mining de Celonis.
Primero, subiremos nuestro archivo CSV o Excel que contiene el registro de eventos. Una vez cargado, podemos configurar la aplicación para que reconozca qué columnas contienen la información clave: marca de tiempo, nombre de actividad e ID de caso.

Con su explorador de procesos, es bastante fácil visualizar el proceso que hemos rastreado con el sistema RTLS.
El explorador ofrece entonces al usuario una visión directa de los distintos aspectos que puede analizar con más detalle.
Lo primero que exploraremos es la pregunta: “¿Cómo es tu proceso?” Esto se relaciona con el descubrimiento de procesos y permite al usuario visualizar su proceso.
A partir de esto, vemos claramente que los pedidos comienzan con la tarea Llegada de mercancías y luego continúan en una de las dos líneas de producción.

El proceso concluye después de que el pedido sale de la ubicación Embalaje y envío.
La herramienta también nos ofrece deslizadores que pueden utilizarse para filtrar las rutas menos comunes. Cuando mostramos todas las rutas, aparecen dos adicionales.
La identificación de estas dos rutas es un ejemplo de verificación de conformidad. Al investigar esta vista, observamos que en ocasiones no se siguió el flujo del proceso.
En la primera desviación, observamos que en la primera línea de producción se omitió el paso de pruebas para varios trabajos. Esto probablemente indica un posible problema de calidad en esa línea de producción.
En la segunda desviación, vemos que algunos productos fueron devueltos a un paso anterior después de la prueba del producto. Esto sugiere que ciertos productos terminados encontraron problemas durante las pruebas y necesitaron retrabajo.

Estos primeros pasos ya nos muestran rápidamente los beneficios y el valor de utilizar una herramienta de process mining para analizar más a fondo los datos. Solo con el registro de eventos, pudimos visualizar nuestro proceso tal y como se ejecuta en la fábrica y validar la conformidad del proceso.
Ahora profundicemos en la tercera técnica: Mejora de procesos.
Comenzaremos una nueva exploración llamada “¿Cuánto tarda tu proceso?”
En esta exploración, la herramienta analiza el tiempo de ciclo de nuestro proceso. Revela que se han investigado 1,68 mil casos, y que el 94 % de estos casos tiene un tiempo de ciclo de tres días o menos.

Este tipo de vista general es increíblemente útil, ya que ofrece de inmediato una visión del tiempo de ciclo esperado actual. También se traduce en un KPI fácil de seguir para la planta, ya que el usuario puede ajustar el tiempo de ciclo esperado y ver al instante cómo se compara la distribución actual.
Además, la herramienta permite a los usuarios realizar un análisis más profundo, lo que les permite seguir la evolución del tiempo de ciclo a lo largo del tiempo, identificando tendencias, anomalías o periodos de mejora y retraso.
También es posible profundizar en el tiempo de ciclo entre tareas y ver el número de casos por día, pero esto ya nos ha dado una buena primera idea de lo que es posible con esta herramienta.
Profundizando en los tiempos de ciclo y espera con IBM Process Mining
Con IBM Process Mining, seguimos un flujo de trabajo muy similar para cargar nuestro registro de eventos en la herramienta. Como antes, debemos especificar qué columnas corresponden al ID de caso (aquí denominado ID de proceso), la actividad y la marca de tiempo. Sin embargo, una diferencia notable es que IBM Process Mining nos permite etiquetar dos columnas separadas: una para la hora de inicio y otra para la hora de fin. Esto permite a la herramienta diferenciar claramente entre el tiempo dedicado a realizar una actividad y el tiempo de espera entre actividades, una función que no está tan fácilmente disponible en la aplicación Celonis Business Miner.
Una vez que el registro de eventos está correctamente configurado y etiquetado, la herramienta presenta su análisis del proceso. La representación visual del modelo de proceso es bastante similar a la de Celonis.

Una función que merece destacarse es la posibilidad de seleccionar la opción “Retrabajo”. Al activarla, se resalta automáticamente la sección del proceso identificada previamente como retrabajo. De forma impresionante, la herramienta realiza este análisis de variantes sin requerir ninguna entrada adicional por parte del usuario.

A continuación, utilizamos esta herramienta para explorar oportunidades de optimización y mejora de procesos. Al examinar los análisis, observamos rápidamente un desequilibrio en la carga de trabajo entre las dos líneas de producción: la Línea de producción 2 gestiona alrededor del 65 % de todos los trabajos. Además, hay una diferencia notable en los tiempos de ciclo. De media, los pedidos en la Línea de producción 1 se completan en 2 días y 9 horas, frente a 2 días y 16 horas en la Línea de producción 2.
A primera vista, esto sugiere que la planta podría mejorar la eficiencia trasladando más pedidos a la Línea de producción 1, que actualmente está menos utilizada y tiene un tiempo de ciclo más rápido.
Después examinamos el modelo de proceso para revisar la duración media de cada tarea. Como se indicó anteriormente, la herramienta desglosa cómodamente la duración de cada tarea en dos partes: tiempo de servicio y tiempo de espera.
La visualización resultante facilita la identificación de estos tiempos en cada paso del proceso. Se hacen evidentes diferencias claras entre las dos líneas de producción, lo que ofrece más oportunidades de optimización tras un análisis más detallado.
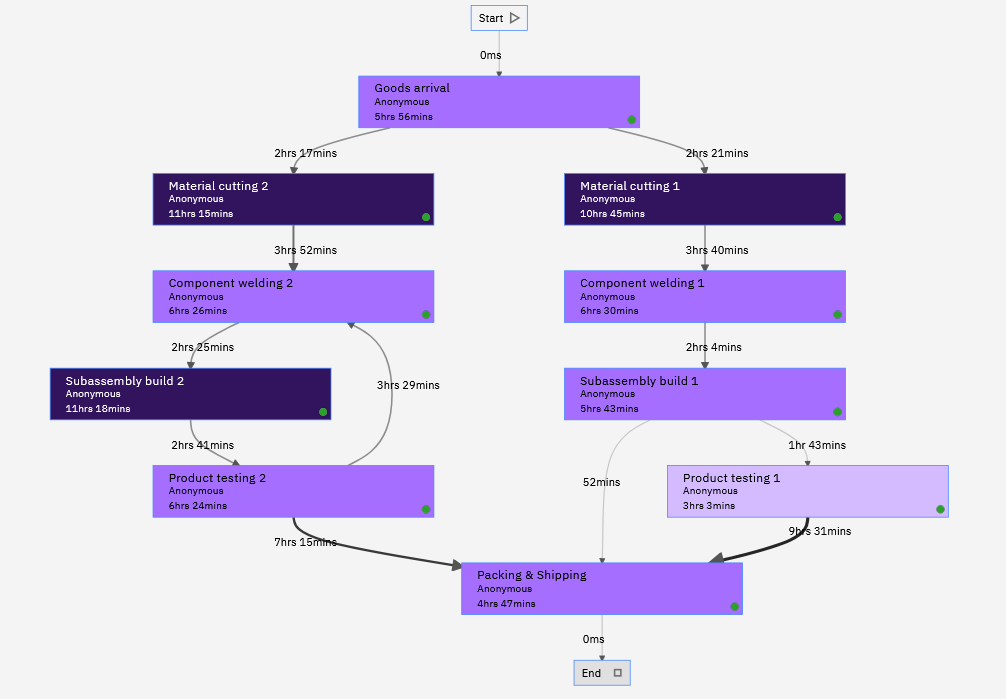
Analizando el registro de eventos con Python
Como paso final de este análisis, veremos cómo podemos visualizar el registro de eventos con Python. Para realizar process mining en Python, utilizaremos la biblioteca PM4Py. Esta biblioteca admite algoritmos de process mining de última generación en Python. A diferencia de las herramientas anteriores, esta herramienta es de código abierto. Sin embargo, tiene la desventaja de que tendrás que hacer la mayor parte del análisis por tu cuenta, ya que no hay una interfaz de usuario que te guíe en la exploración de datos.
Intentaremos recrear algunos resultados que también se encontraron con las herramientas anteriores. Primero, importaremos nuestro registro de eventos e intentaremos obtener una visualización de nuestro modelo de proceso.
La forma en que cargamos el registro de eventos es muy similar a la anterior:
- Cargamos el registro de eventos usando pandas, que es una biblioteca de Python muy popular para el análisis de datos.
- Etiquetamos las columnas con ID de caso, actividad, marca de tiempo de inicio y de fin.
También podemos extraer con bastante facilidad el modelo de proceso del registro de eventos. En una de las vistas básicas nos muestra un grafo dirigido del proceso con la frecuencia de cada trabajo en los nodos y las aristas.

Es posible realizar más análisis, así como una extracción del modelo BPMN. Pero concluiremos aquí nuestra обзор. Parte del código de ejemplo utilizado para generar esta figura puede encontrarse en el archivo adjunto.
Información basada en la ubicación con RTLS
Como se puede ver en el ejemplo anterior, los datos de ubicación pueden generar muchos tipos distintos de información. Aunque las soluciones RTLS suelen utilizarse para analizar el movimiento de activos y los procesos operativos dentro de las instalaciones, otras plataformas de analítica se centran en patrones geográficos entre múltiples ubicaciones. Por ejemplo, los minoristas pueden analizar redes de tiendas para obtener información sobre la experiencia del cliente en distintas ubicaciones, ofreciendo otra forma de información basada en la ubicación.
Conclusión
Este ejemplo destaca el valor del process mining cuando se combina con datos de ubicación de alta calidad, y cómo puede descubrir información accionable sobre los procesos operativos. Este ejemplo demostró cómo la plataforma Pozyx puede proporcionar el crucial registro de eventos basado en ubicación que sirvió de base para todo el análisis.
Al hacer un seguimiento preciso del movimiento de los trabajos a través del proceso de producción y convertir esas actualizaciones de ubicación en registros de eventos estructurados, nuestra solución permitió una integración fluida con herramientas líderes de process mining como Celonis Business Miner, IBM Process Mining y la biblioteca de código abierto PM4Py en Python. Cada herramienta aprovechó el registro de eventos que proporcionamos para visualizar los flujos reales del proceso, identificar desviaciones, medir los tiempos de ciclo y descubrir oportunidades de optimización.
Los resultados demostraron claramente el valor añadido de combinar datos de ubicación con técnicas de process mining, al poner de manifiesto ineficiencias, confirmar la conformidad del proceso y apoyar la toma de decisiones basada en datos.
Aunque este ejemplo se centró en un caso de uso de fabricación, el mismo enfoque es aplicable en sectores como la logística, la sanidad y otros. Como proveedor de la infraestructura RTLS y de los datos de eventos, ayudamos a nuestros clientes a aprovechar este potencial dentro de sus propias operaciones.
Si buscas obtener información operativa más profunda u optimizar tus procesos, nuestro Pozyx UWB RTLS y la plataforma Pozyx pueden servir como la base perfecta para tu próximo proyecto de process mining.
Escrito por
Jeroen Van Hecke

Ingeniero sénior de I+D en Pozyx
Jeroen Van Hecke es ingeniero sénior de I+D en Pozyx, donde se centra en el desarrollo de algoritmos y la optimización de sistemas para soluciones de localización en tiempo real. Con formación en ingeniería eléctrica y un doctorado por la Universidad de Gante, aporta tanto rigor académico como experiencia práctica a la innovación industrial.



